โดยอัตโนมัติบริษัทที่อยู่เบื้องหลังมัน WordPress และ Tumblr กำลังเจรจาเพื่อสร้างรายได้จากเนื้อหาของผู้ใช้โดยการขายข้อมูลให้กับบริษัทปัญญาประดิษฐ์ รวมถึง MidJourney และ OpenAI. ข้อมูลนี้จากแพลตฟอร์มบล็อก Tumblr และ WordPress.com จะถูกนำมาใช้ในการฝึกอบรม modeของเอไอ
แม้ว่ารายละเอียดของธุรกรรมยังไม่ชัดเจน แต่ข่าวดังกล่าวได้ก่อให้เกิดความกังวลในหมู่ผู้ใช้เกี่ยวกับการใช้เนื้อหาส่วนตัวของตนในทางที่ผิดบนแพลตฟอร์มบล็อกทั้งสอง 404 Media ยังชี้ให้เห็นว่าความขัดแย้งภายในเกิดขึ้นภายใน Automattic เนื่องจากเนื้อหาที่รวบรวมมีข้อมูลส่วนตัวที่ไม่ได้ตั้งใจจะเก็บไว้ภายในบริษัท
เพื่อตอบสนองต่อฟันเฟืองดังกล่าว Automattic จะเปิดตัวฟีเจอร์ใหม่ที่จะอนุญาตให้ผู้ใช้เลือกที่จะไม่แบ่งปันข้อมูลของตนสำหรับการฝึกอบรม AI ในบล็อกโพสต์ บริษัทยืนยันความมุ่งมั่นในการให้บริการผู้ใช้ Tumblr และ WordPress ควบคุมเนื้อหาได้มากขึ้น โดยกล่าวถึงการเปิดตัวการตั้งค่าเพื่อ "กีดกันการสำรวจโดยบริษัท AI" โดยอธิบายว่าแพลตฟอร์มการสำรวจ AI ชั้นนำถูกบล็อกโดยค่าเริ่มต้น
ปัญหาการใช้เนื้อหาจากบล็อกของบริษัทที่พัฒนา modele AI ไม่ได้จำกัดอยู่เพียงแพลตฟอร์มที่จัดการโดยบริษัท Automattic เท่านั้น มากมาย OpenAI เช่น Google ให้ใช้ซีบอทrawโดยที่ฉันรวบรวมข้อมูลจากเว็บไซต์ทั้งหมดเพื่อฝึกอบรม modeปัญญาประดิษฐ์ กระบวนการนี้คล้ายกับการรวบรวมข้อมูลโดยเครื่องมือค้นหา
บล็อคได้ยังไง. OpenAI และราศีเมถุน (กวี) เอาข้อมูลจากบล็อกของคุณเหรอ?
หากคุณเป็นเจ้าของบล็อกหรือเว็บไซต์และไม่ต้องการให้ข้อมูลจากบล็อกนั้นนำไปใช้ในการฝึกอบรม modeของปัญญาประดิษฐ์ OpenAI และราศีเมถุน คุณสามารถบล็อกบอทได้ (คrawlers) ไปยังเนื้อหา ข้อจำกัดนี้สามารถตั้งค่าได้ผ่านไฟล์ robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
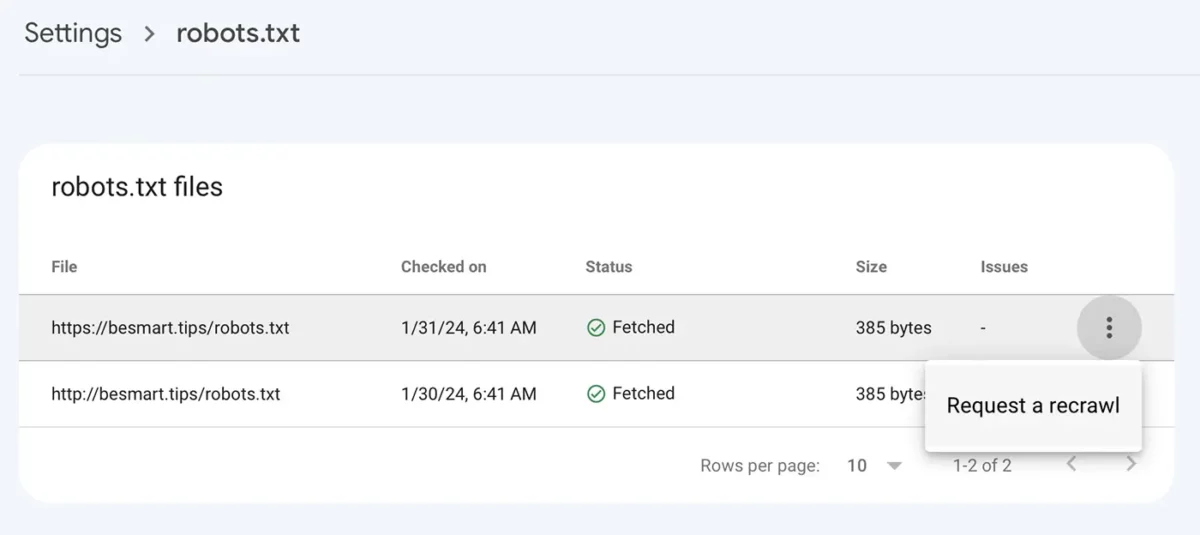
Disallow: /หลังจากที่คุณบันทึกไฟล์ robots.txt ด้วยการขึ้นบรรทัดใหม่แล้ว ให้ไปที่ Google Console เพื่อ: Settings > robots.txt > คลิกที่เมนูที่มีจุดสามจุด คลิก "Request a recrawl"
ที่เกี่ยวข้อง GPT-5 และเว็บครอลเลอร์ใหม่ GPTBot ที่พัฒนาโดย OpenAI.
สำหรับผู้ใช้ Tumblr และ WordPressการเข้าถึงการดึงข้อมูลจากบล็อกโดย OpenAI หรือบริษัทพัฒนาปัญญาประดิษฐ์อื่นๆ จะสามารถถูกบล็อกได้โดยใช้เครื่องมือที่บริษัท Automattic จัดให้