ส่วนใหญ่เมื่อคุณต้องการบล็อกการเข้าถึง SeekportBot หรืออื่นๆ crawl bots กับเว็บไซต์ เหตุผลง่ายๆ สไปเดอร์ของเว็บทำให้มีการเข้าถึงมากเกินไปในช่วงเวลาสั้นๆ และร้องขอทรัพยากรของเว็บเซิร์ฟเวอร์ หรือมาจากเครื่องมือค้นหาที่คุณไม่ต้องการให้เว็บไซต์ของคุณถูกสร้างดัชนี
เป็นประโยชน์อย่างมากสำหรับเว็บไซต์ที่เข้าชมโดยคrawฉันชนเขา สไปเดอร์เว็บเหล่านี้ออกแบบมาเพื่อสำรวจ ประมวลผล และจัดทำดัชนีเนื้อหาของหน้าเว็บในเครื่องมือค้นหา Google และ Bing ใช้คrawฉันชนเขา อย่างไรก็ตาม ยังมีเครื่องมือค้นหาที่ใช้หุ่นยนต์เพื่อรวบรวมข้อมูลจากหน้าเว็บ Seekport เป็นหนึ่งในเครื่องมือค้นหาเหล่านี้ ซึ่งใช้คrawโปรแกรม SeekportBot สำหรับจัดทำดัชนีหน้าเว็บ น่าเสียดายที่บางครั้งใช้มันมากเกินไปและสร้างการรับส่งข้อมูลโดยไม่จำเป็น
เนื้อหา
SeekportBot คืออะไร
SeekportBot เป็น web crawler พัฒนาโดยบริษัท Seekportซึ่งตั้งอยู่ในเยอรมนี (แต่ใช้ IP จากหลายประเทศ รวมทั้งฟินแลนด์) บอทนี้ใช้เพื่อรวบรวมข้อมูลและจัดทำดัชนีเว็บไซต์เพื่อให้สามารถแสดงในผลลัพธ์ของเครื่องมือค้นหา Seekport. เครื่องมือค้นหาที่ใช้งานไม่ได้ เท่าที่ฉันสามารถบอกได้ อย่างน้อยที่สุด ก็ไม่ได้แสดงผลลัพธ์สำหรับวลีสำคัญใดๆ ให้ฉัน
SeekportBot การใช้งาน user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"วิธีบล็อกการเข้าถึง SeekportBot หรือคrawฉันคลิกที่เว็บไซต์
หากคุณได้ข้อสรุปว่าเว็บสไปเดอร์นี้หรือเว็บอื่นๆ คุณไม่จำเป็นต้องสแกนทั้งเว็บไซต์ของคุณและทำการรับส่งข้อมูลโดยไม่จำเป็นไปยังเว็บเซิร์ฟเวอร์ คุณมีหลายวิธีที่คุณสามารถบล็อกการเข้าถึงได้
ไฟร์วอลล์ในระดับเว็บเซิร์ฟเวอร์
เป็นแอปพลิเคชันไฟร์วอลล์ open-source ซึ่งสามารถติดตั้งบนระบบปฏิบัติการ Linux และสามารถกำหนดค่าให้บล็อกทราฟฟิกตามเกณฑ์ต่างๆ ที่อยู่ IP ตำแหน่ง พอร์ต โปรโตคอล หรือตัวแทนผู้ใช้
APF (Advanced Policy Firewall) เป็นซอฟต์แวร์ที่คุณสามารถบล็อกบอทที่ไม่ต้องการในระดับเซิร์ฟเวอร์ได้
เนื่องจาก SeekportBot และเว็บสไปเดอร์อื่นๆ ใช้บล็อก IP หลายบล็อก กฎการบล็อกที่มีประสิทธิภาพสูงสุดจึงอิงตาม "user agent". ดังนั้น หากคุณต้องการบล็อกการเข้าถึง SeekportBot โดย APFสิ่งที่คุณต้องทำคือเชื่อมต่อกับเว็บเซิร์ฟเวอร์ผ่าน SSHและเพิ่มกฎตัวกรองในไฟล์การกำหนดค่า
1. เปิดไฟล์คอนฟิกด้วย nano (หรือสำนักพิมพ์อื่น).
sudo nano /etc/apf/conf.apf2. มองหาบรรทัดที่ขึ้นต้นด้วย “IG_TCP_CPORTS” และเพิ่มตัวแทนผู้ใช้ที่คุณต้องการบล็อกที่ส่วนท้ายของบรรทัดนี้ ตามด้วยเครื่องหมายจุลภาค ตัวอย่างเช่น หากคุณต้องการบล็อก user agent "SeekportBot" บรรทัดควรมีลักษณะดังนี้:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. บันทึกไฟล์และเริ่มบริการ APF ใหม่
sudo systemctl restart apf.serviceการเข้าถึง "SeekportBot" จะถูกบล็อก
กรอง web crawls ด้วยความช่วยเหลือของ Cloudflare – บล็อกการเข้าถึง SeekportBot
ด้วยความช่วยเหลือของ Cloudflare ฉันคิดว่าเป็นวิธีที่ปลอดภัยและสะดวกที่สุดสำหรับฉัน โดยคุณสามารถจำกัดการเข้าถึงของบอทบางตัวไปยังเว็บไซต์ได้หลายวิธี วิธีการที่ฉันใช้ในกรณี SeekportBot เพื่อกรองการเข้าชมร้านค้าออนไลน์
สมมติว่าคุณมีเว็บไซต์ที่เพิ่มไปยัง Cloudflare และบริการ DNS เปิดใช้งานแล้ว (นั่นคือ การรับส่งข้อมูลไปยังเว็บไซต์จะต้องผ่าน Cloudflare) ให้ทำตามขั้นตอนด้านล่าง:
1. เปิดบัญชี Clouflare ของคุณและไปที่เว็บไซต์ที่คุณต้องการจำกัดการเข้าถึง
2. ไปที่: Security → WAF และเพิ่มกฎใหม่ Create rule.
3. เลือกชื่อสำหรับกฎใหม่ Field: User Agent - Operator: Contains - Value: SeekportBot (หรือชื่อบอทอื่น) – Choose action: Block - Deploy.
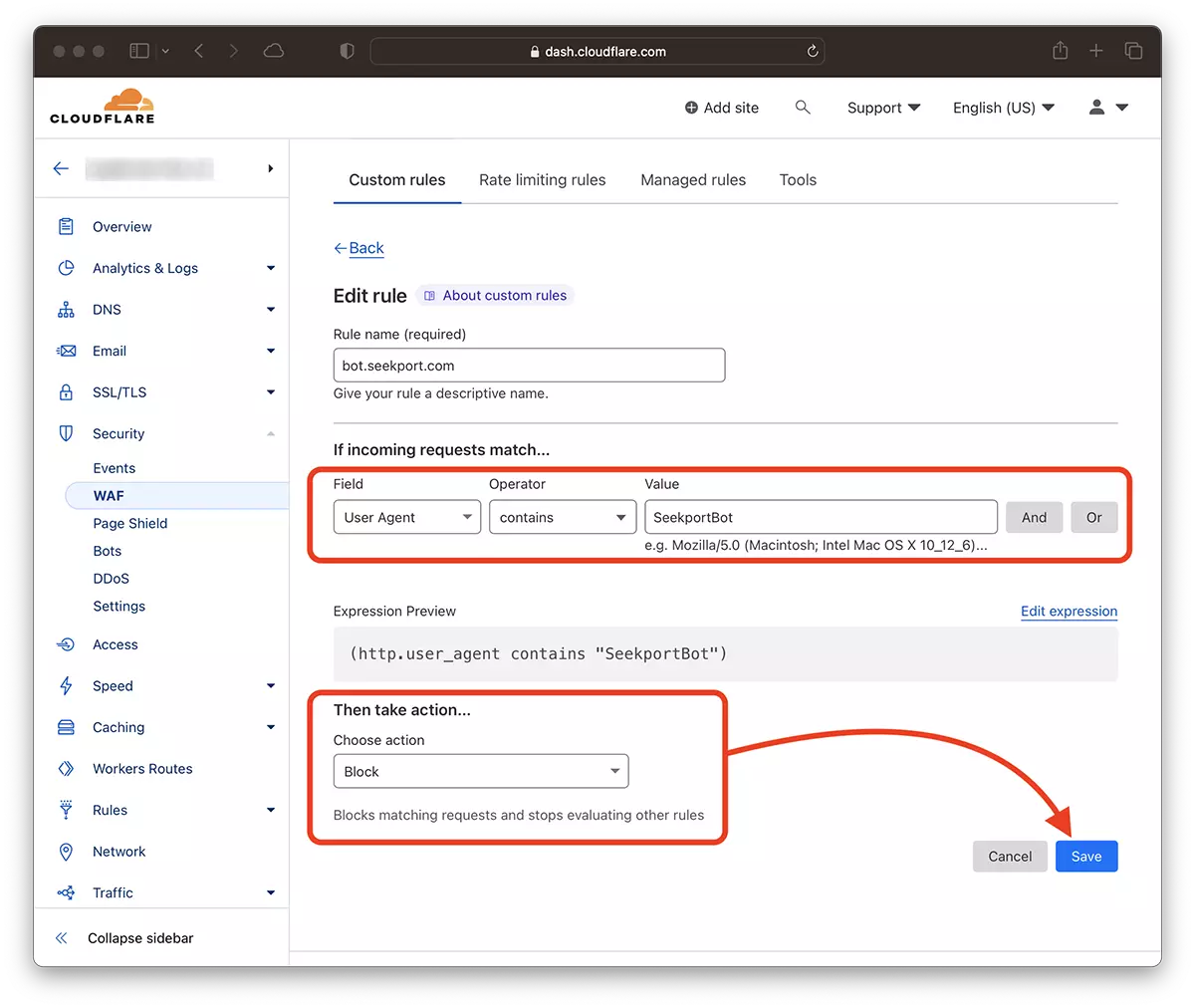
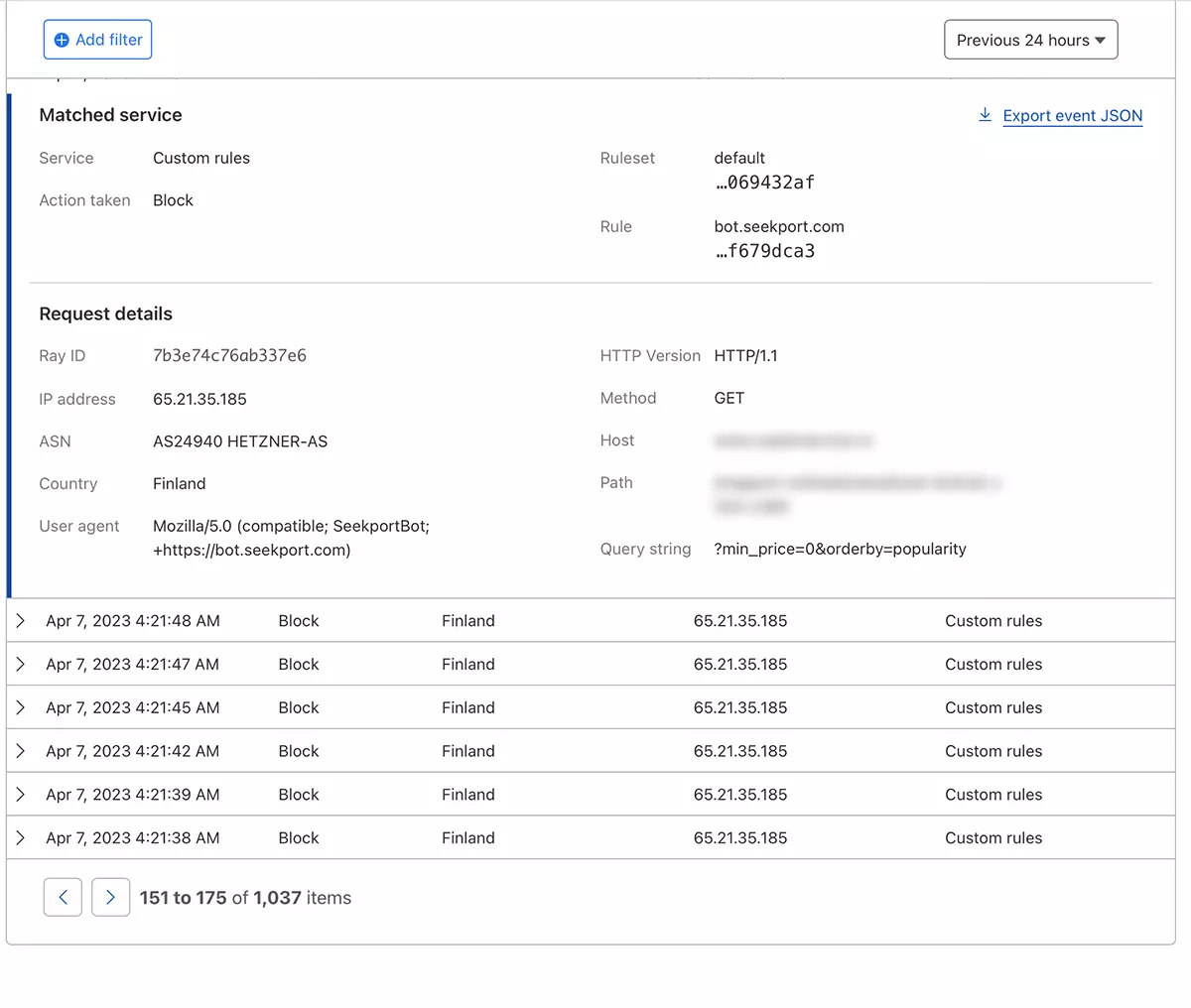
ในเวลาเพียงไม่กี่วินาที กฎใหม่ WAF (Web Application Firewall) มันเริ่มมีผลบังคับใช้
ตามทฤษฎีแล้ว ความถี่ที่เว็บสไปเดอร์เข้าถึงเว็บไซต์สามารถตั้งค่าได้ robots.txt, แต่... เป็นเพียงในทางทฤษฎีเท่านั้น
User-agent: SeekportBot
Crawl-delay: 4หลาย web crawlerii (ยกเว้น Bing และ Google) ไม่ปฏิบัติตามกฎเหล่านี้
โดยสรุป หากคุณระบุเว็บคrawl ผู้ที่เข้าถึงไซต์ของคุณมากเกินไป วิธีที่ดีที่สุดคือบล็อกการเข้าถึงของเขาโดยสิ้นเชิง แน่นอนถ้าบอทนี้ไม่ได้มาจากเครื่องมือค้นหาที่คุณสนใจที่จะนำเสนอ